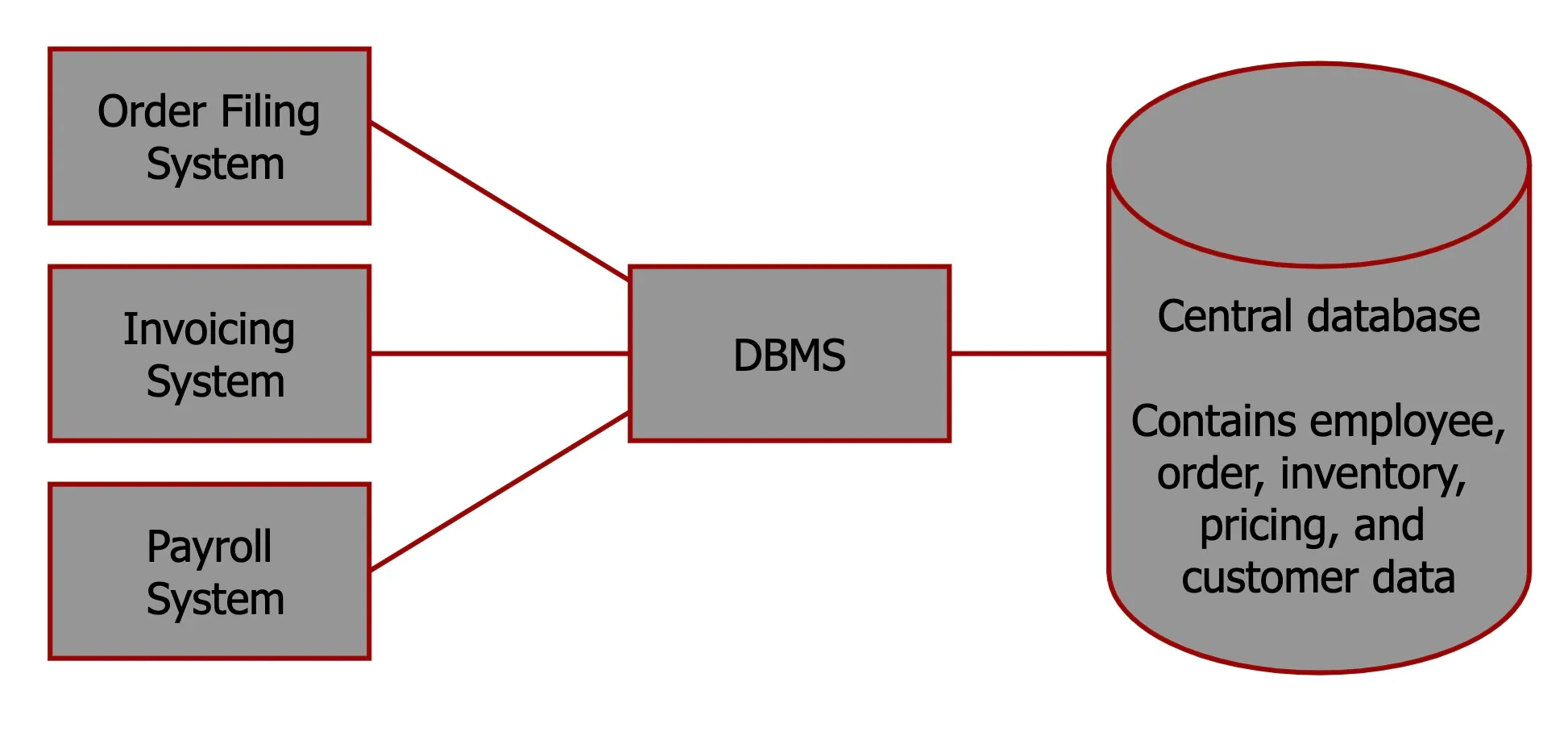
Database Management Systems
A software system that is used to create, maintain, and provide controlled access to user databases.
What is NoSQL?
NoSQL is a non-relational database management system, different from traditional relational database management systems in some significant ways.
It is designed for distributed data stores where very large scale of data storing needs (for example Google or Facebook which collects terabites of data every day for their users).
These types of data storing may not require fixed schema, avoid join operations and typically scale horizontally.
Why NoSQL?
Nowadays, data is becoming easier to access and capture through third parties such as Facebook, Google and others.
Personal user information, social graphs, geolocation data, user-generated content and machine logging data are just a few examples where the data has been increasing exponentially.
To avail the above serivce properly, it is required to process huge amount of data. Which SQL databases were never designed to handle.
The evolution of NoSQL databases is to handle the huge amount of data properly.
”Schema-less models”: Increasing Flexibility for Data Manipulation
NoSQL data systems hold out the promise of greater flexibility in database management while reducing the dependence on more formal database administration.
NoSQL databases have more relaxed modeling constraints which may benefit both the application developer and the end-user analysts when their interactive analyses are not throttled by the need to cast each query in terms of a relationship table-based environment.
NoSQL Categories
There are four general types (most common categories) of NoSQL databases.
Each of these categories has its own specific attributes and limitations.
There is not a single solution which is better than all others, however there are some databases that are better to solve specific problems.
The four categories are:
- Key-Value Stores
- Column-oriented databases
- Document-oriented databases
- Graph databases
Key-Value Stores
Key-value stores are the most basic types of NoSQL databases, similar to a phone directory where names and numbers are mapped together.
Designed to handle huge amounts of data, they are based on Amazon’s Dynamo paper.
Key-value stores allow developers to store schema-less data.
In the key-value storage, the database stores data as a hash table, where each key is unique and the value can be a string, JSON, BLOB (Binary Large Object) or any other format.
A key may be strings, hashes, lists, sets, sorted sets and values are stored against these keys.
Some examples are Riak, Voldemort, Redis.
Column-oriented databases
Column-oriented databases primarily work on columns and every column is treated individually.
Values of a single column are stored contiguously.
Column stores data in column specific files.
In Column stores, query processors work on columns too.
All data within each column data file have the same type which makes it ideal for compression.
Column stores can improve the performance of queries as it can access specific column data.
High performance on aggregation queries (e.g., COUNT, SUM, AVG, MIN, MAX).
Works on data warehouses and business intelligence, customer relationship management (CRM), Library card catalogs etc.
Examples are HBase, Cassandra.
Document-oriented databases
A collection of documents, data in this model is stored inside documents.
A document is a key-value collection where the key allows access to its value.
Documents are not typically forced to have a schema and therefore are flexible and easy to change.
Documents are stored into collections in order to group different kinds of data.
There are many key-value pair methods, e.g., Hash-tag is used as the key to access the value, path or URL.
Example is MongoDB, DynamoDB, CosmosDB.
Graph databases
A graph data structure consists of a finite (and possibly mutable) set of ordered pairs, called edges or arcs, of certain entities called nodes or vertices.
A graph database stores data in a graph structure.
It is capable of elegantly representing any kind of data in a highly accesible way.
A graph database is a collection of nodes and edges.
Each node represents an entity (such as a student or business) and each edge represents a connection or relationship between two nodes.
Every node and edge is defined by a unique identifier, where each node knows its adjacent nodes.
Everything is indexed, so we use this for lookups.
Examples are Neo4j, HyperGraphDB.
NoSQL VS. SQL
| NoSQL | SQL | |
|---|---|---|
| Intended Purpose | Specific use case | General purpose |
| API | SQL not required | SQL required |
| Data Model | Various, depending on NoSQL database type | Tables with fixed rows and columns |
| Schema | Flexible | Rigid |
| Scalability | Horizontal scale out | Vertical scale up |
| Data Integrity | BASE | ACID |
BASE: Basically Available, Soft state, Eventual consistency.
ACID: Atomicity, Consistency, Isolation, Durability.